
개발하는 뚱이
🦕SVM이란??(Ei : Ez Ai) 본문
서포트 백터 머신(support vector machine)이란??
주어진 데이터가 어느 카테고리에 속하는지 분류하는 이진 분류 모델입니다.
SVM은 N차원의 공간을 N-1차원으로 나눌 수 있는 초평면을 찾는 기법입니다.
이제 차근차근 알아보도록 합시다.
마진과 서포트 백터

위 사진은 클래스 0과 클래스 1을 이진분류한 사진입니다.
SVM은 2개의 클래스를 이진 분류할 수 있는 구분선(결정 경계)을 찾고자 합니다.

여기서 구분선(결정 경계)이라는 것은 마진을 최대화한 선입니다.
여기서 마진은 각 클래스 중 가장 끝에 있는 데이터의 거리입니다.
그리고 각 클래스 중 가장 끝에 있는 데이터를 서포트 백터라고 합니다.
서포트 백터라 하는 이유!
데이터들의 위치에 따라 초평면의 위치가 달라지기 때문에 초평면 함수를 지지한다는 의미를 가지고 있음
마진을 최대화한다는 것이 무슨 뜻일까??

이 3가지선중 마진을 최대화한 것은 가운데 선입니다.
왼쪽 선은 파란 서포트 벡터와의 거리는 길지만 빨간 서포트 벡터와의 거리는 짧습니다. 오른쪽은 왼쪽과 반대 상황입니다.
반면 가운데 선은 빨간 서포트 벡터, 파란 서포트 벡터와의 거리가 같습니다.
방금 설명에서도 알 수 있듯이 최대화라는 말은 최적의 선이라 생각하시면 됩니다.
N차원의 공간을 (N-1) 차원으로 나눌 수 있는 초평면
위 상황에서 우리는 2차원 데이터(공간)로 구분선을 찾았습니다.
여기서 구분선은 (2-1) 차원의 선이었습니다. 그렇다면 3차원 데이터는 어떻게 구분할까요?

바로 (3-1) 차원인 2차원으로 구분합니다.
이렇듯 초평면이라는 뜻은 2차원이 아닌 고차원에서도 분류를 할 수 있는 경계를 의미합니다.
이제 SVM에 기초를 살펴보았습니다.
이제 우리는 좀 더 자세한 선형 SVM의 작동과 비선형 SVM 작동에 대해 알아볼 것입니다.
선형 SVM
소프트 마진
소프트 마진은 하드마진의 한계를 개선하고자 나온 기법입니다.
하드마진은 오차가 없이 초평면을 불리하려 하지만 소프트 마진은 약간의 오차를 허용하는 방법입니다.
이때 slack variable을 사용합니다.
slack variable은 해당 결정 경계로부터 잘못 분류된 데이터의 거리를 측정하기 위해 사용됩니다.
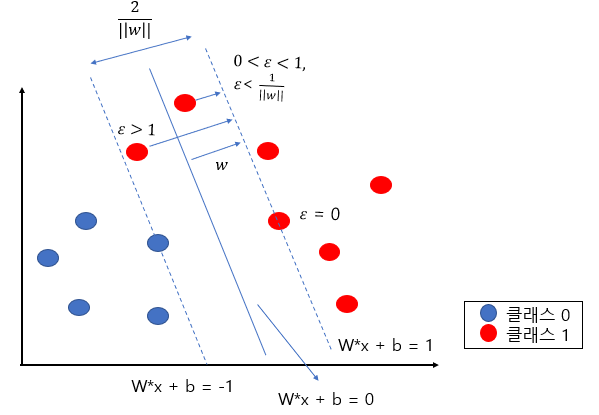
- e = 0 올바른 분류
- 0 < e < 1 올바른 분류이지만 서포트 벡터보다 초평면에 가까운 경우
- e > 1 잘못 분류된 경우
비선형 SVM
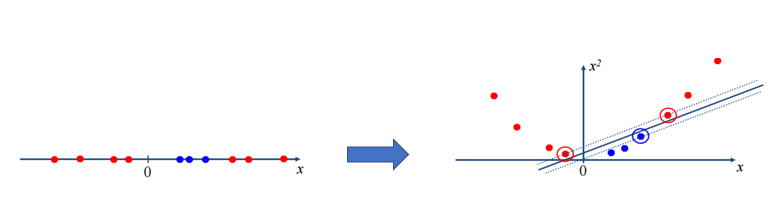
위 그림처럼 원래는 선형 분리가 불가능하지만 이를 해결하기 위해 데이터를 2차원으로 만든 후 선형 분리를 하였습니다.
이처럼 비선현 분리는 선형 분리가 불가능한 원래의 공간(입력 공간)에서 선형 분리 가능한 고차원 공간(특성 공간)으로 성형 분리를 진행 후 다시 기존의 공간으로 변환하여 비선형 분리를 하는 것입니다.
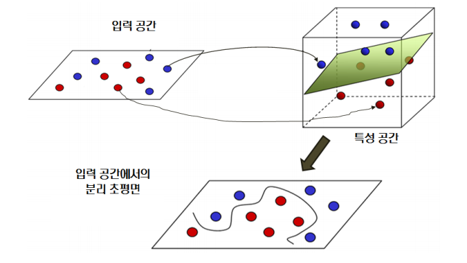
입력 공간에서 특성 공간으로 변환하기 위해서는 커널 트릭이 사용합니다.
사실 커널 트릭은 데이터를 고차원 공간으로 옮기지 않아도, 마치 고차원 공간에서 계산하는 것처럼 작용되는 방법입니다.
이를 위해 커널 함수라는 것이 존재하는데, 커널 함수는 아래와 같습니다.
- 선형 커널(Linear kernel) : 데이터를 고차원 공간으로 매핑하지 않고도 선형 분리 가능한 경우 사용
- 다항식 커널(Polynomial kernel): 데이터를 고차원 다항식 공간으로 매핑하여 비선현 패턴을 잡음
- 가우시안 라디언스 베이스 함수(RBF) 커널 : 데이터를 무한 차원의 공간으로 매핑하여 비선형 패턴을 잡아냄
간단 요약
- SVM : 주어진 데이터가 어느 카테고리에 속하는지 분류하는 이진 분류 모델
- SVM은 마진을 최대화한 선을 찾는 것이 목표
- 선형 SVM은 하드 마진을 보안한 소프트 마진이 있음
- 비선형 SVM은 커널 트릭을 활용하여 계산됨(선형 커널, 다항식 커널, RBF 커널이라는 커널 함수가 존재)
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
cancer = datasets.load_breast_cancer()
x = cancer.data
y = cancer.target
scaler = StandardScaler()
x_scaler = scaler.fit_transform(x)
x_train, x_test, y_train, y_test = train_test_split(x_scaler, y, test_size=0.3)
model = SVC(kernel='rbf', gamma='scale', C=1.0) # gamma는 결정 경계의 곡률을 의미, C는 마진의 크기 조절
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print("정확도 (Accuracy):", accuracy_score(y_test, y_pred))
코드를 읽어 보면서 흐름을 아는 것이 중요합니다.
이해가 안 되더라도 한 번씩 읽어보는 것을 권장합니다.
언제나 배우며 성장하는 학생입니다.
정리한 것 중 잘못된 거나 추가 사항이 있으시다면 피드백을 남겨주시면 정말 감사하겠습니다.
이메일 : hyohyeonkim08@gmail.com
'Ei(Ez Ai)' 카테고리의 다른 글
| 💣릿지 & 라쏘 회귀란??(Ei : Ez Ai) (4) | 2024.11.02 |
|---|---|
| 🛬손실함수와 경사하강법이란??(Ei : Ez Ai) (2) | 2024.10.20 |
| 🌲의사결정 트리란??(Ei : Ez Ai) (6) | 2024.10.05 |
| 🐍로지스틱 회귀란 무엇일까?? (Ei : Ez Ai) (2) | 2024.10.02 |
| 🦢선형 회귀란 무엇일까?? (Ei : Ez Ai) (2) | 2024.09.23 |



